据外媒报导,一家中国AI公司秘密携带装有4.8PB数据的硬盘到马来西亚,在当地的算力中心租用了300台Nvidia GPU服务器进行模型训练。
这个路径完全绕过了美国对中国的Nvidia芯片封锁,可算作是一种“创新”之法。

这家公司为了不引起注意,还把硬盘分给4个人携带,每个人15块硬盘,据称这是一次精心策划的操作,筹备过程历时数月。
但是从这件事中透露出信息颇令人玩味,引起网上各种针锋相对的评论,首先,有人质疑为什么不从网上传输,还要人肉送硬盘,不合常规。
但实际上,人肉运输确实是快速且低成本的方式,如下图所示,这是在不同的网络传输速度下,传完4.8PB数据所需时长:
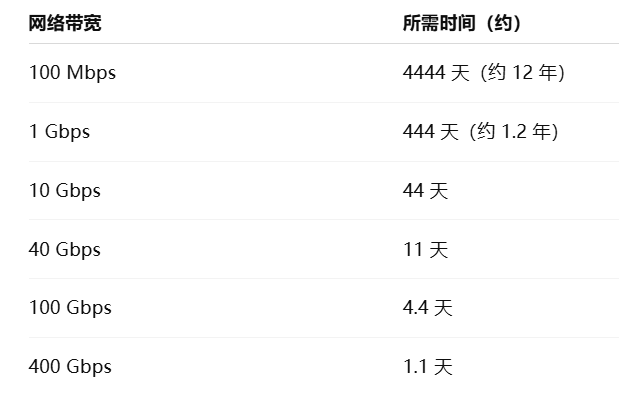
从图中可看出,即使用专线(如阿里云国际专线),跨境传4.8PB也可能需要几十天,这还是在理想状态下,比如无带宽抖动、无掉包、无数据压缩,且始终跑满带宽。而现实中的跨境数据传输往往达不到理论峰值。 况且如此大数据量的数据传输,在网上很容易被监控到,而人肉运输反而比较低调。
那么另一个问题来了,携带大量数据出入境,在任何国家都是一个很可疑的行为,为什么在海关没受到阻拦?
在马来西亚,携带硬盘或SSD出入境并不构成非法,可能也不需要申报。海关也没有能力或权限在现场读取硬盘数据,硬盘很有可能是加密的,现场难以查看。 如果该公司的人持有商务签证或科技展会邀请函,带着笔记本电脑、技术资料等道具,很容易“伪装”为合法的海外交流团队。
马来西亚目前对中国科技企业的监管相对宽松,出入境管理可能并不严格,所以带着硬盘来往并非不可能。
最后一个问题是,为什么这家公司不在国内训练模型?特别是最近有个新闻说“华为创造AI算力新纪录:万卡集群训练98%可用度”。 首先,华为发布的“万卡集群”(据称使用昇腾910系列)确实在AI算力规模上已突破纪录,达到98%高可用度,技术层面显示出其算力调度与基础设施集成能力的进步。
但可替代并不等于完全等价。Nvidia基于CUDA生态,已发展十几年,有大量模型、工具、框架高度适配,华为昇腾基于MindSpore,与全球主流AI开源生态(如PyTorch、TensorFlow等)并不原生适配。对于追求开发效率和通用性能的AI企业,切换到华为集群的成本极高,代价巨大。
另外华为的“万卡集群”更多用于官方主导的大模型项目或战略示范项目,其定位偏向“国家级技术底座”。而这次偷偷将硬盘带去马来西亚训练的企业,显然是商业公司或创业公司,其目标是快速推出自有产品或模型服务,需要灵活适配海外发布、或开源部署、API兼容,可能并不想过度绑定华为技术栈。
而且,在国内模型训练过程须接受严格的安全审查与内容监管,去国外训练,环境相对宽松。可以构建一个可规避内容监管、灵活出海部署的模型训练环境。 所以,此事件背后隐藏的信息远比表面复杂,是一场组织化、流程化的地下跨国行动,显示出一个庞大灰色地带供应链体系已经悄然成熟。




评论 (0)
还没有评论,来说两句吧!