作者:边界之外

想想DeepSeek发布R1时仅仅是5个月前的事,但仿佛过了半个世纪。
这期间AI领域又发生了许许多多技术演变,推出更强更新模型的公司层出不穷,而OpenAI的模型在升级换代方面脚步放缓,让各家AI公司有了追平甚至在某些方面超越的机会。
公众对DeekSeek的热情也在慢慢冷却,谁不喜欢新的东西呢?
豆包、腾讯、阿里等纷纷推出自己的推理模型,实力与DeepSeek也相差无几,更致命的是他们把模型与自己的应用生态相结合,吸引了一大部分使用者。
想当时,我周围一些对AI一无所知的人也能叨上几句DeepSeek,买菜的大妈也拉着我问现在是不是有个很厉害的AI?
在2025年1月,DeepSeek因其V3和R1模型的出色性能和低成本,访问量曾激增,1月27日单日访问量达到4900万次,同比增长614%,超越谷歌Gemini成为全球第二大AI应用。
而现在DeepSeek的APP用户在当初暴涨之后一路跌落
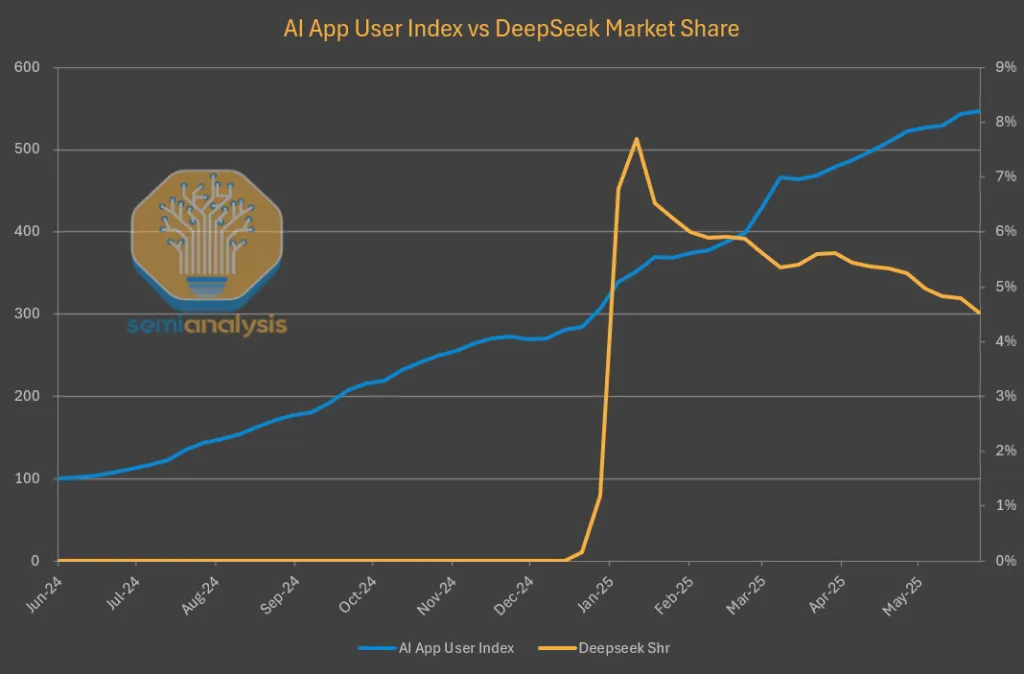
从网页浏览器流量来看,DeepSeek发布以来的数据尤为严峻,流量呈现出明显的下降趋势。与此同时,其他领先的AI模型提供商的用户数均实现了可观的增长。
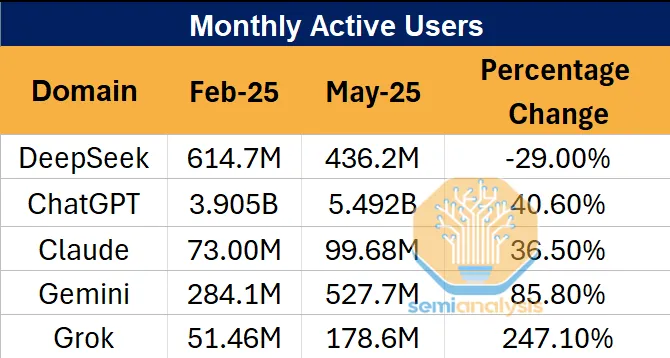
一份来自极客公园的报道指出,DeepSeek的用户使用率从2025年1月的50%暴跌至7月的3%,官网流量同比下滑超过70%。
DeepSeek急需R2来重振号召力,但发布时间一再跳票。
根据The Information的报道,DeepSeek的首席执行官梁文峰对R2模型的当前性能不满意,认为其未达到预期的技术标准,因此决定推迟发布以进一步优化。这表明DeepSeek对质量要求较高,希望R2能在性能上超越前代R1并与顶级竞争对手(如OpenAI的GPT-4o、谷歌的Gemini)匹敌。
美国对高端AI芯片(如Nvidia H100)的出口限制也对DeepSeek的开发工作造成了影响。DeepSeek此前依赖Nvidia H20等芯片进行模型训练,但由于供应受限,可能需要转向华为Ascend芯片或其他国产芯片。这种硬件平台转换需要时间进行适配,可能导致开发进度放缓。
也有消息称,R2的预训练可能已完成,但推理容量不足(即用于模型部署和运行的计算资源),这可能进一步限制了其发布进程。
随着DeepSeek兴起而红火的产品:DeepSeek一体机的热度也迅速降温,不少厂商销售遇冷。
行业逐渐达成共识:顶配一体机的时代已近尾声,接下来将进入中低端机型的“游击战”阶段。
DeepSeek的另一个问题是聚焦基础模型研发而忽略应用生态布局和多模态能力提升,这也将带来不少问题。
首先,基础模型性能优秀,但缺乏行业生态支撑和实际应用方案,会导致模型“高大上”却“不好用”。没有垂直行业API、插件、SDK,客户难以快速集成,商业转化路径模糊,导致ROI低。
其次,深耕基础层但不投入资源构建开发者社区、多模态插件或行业合作,很可能导致别人基于更友好的生态平台(如OpenAI、Google等)进行二次创新,形成虹吸效应,把潜在用户与合作伙伴吸走。
而当前AI技术正朝着“语言+视觉+语音+视频”的多模态方向发展。DeepSeek还没有拿得出手的多模态模型,意味着DeepSeek可能在图像生成、视觉推理、音频理解等应用上被竞争者甩开。
DeepSeek热潮消退,一部分原因也是因为它是开源的,在其它服务提供商部署了之后,分流了其官网的流量,据大型API服务商Openrouter上的Token统计,Deepseek V3的Token量一直位居前3,是唯一进入前10的国产模型。
这证明DeepSeek的模型实力仍在,但急需保持创新能力,加速迭代,才有可能占据AI行业一席之地。




评论 (0)
还没有评论,来说两句吧!