 你知识库中的笔记是否很少打开过,一直在吃灰?LLM Wiki 这个框架可以把你的知识库打造成一个持续进化的数字大脑。
你知识库中的笔记是否很少打开过,一直在吃灰?LLM Wiki 这个框架可以把你的知识库打造成一个持续进化的数字大脑。
你的知识库,是不是也这样
我遇到过的很多人平时都会收藏或保存各种文章,堆积在自己的笔记软件中,如 Obsidian、Evernote 之类。
但真正会坚持日复一日整理和回顾自己笔记的人极少,而且这样做的人也会付出大量的时间和精力,个人知识库能产出的作用也非常有限。
我最近发现一个很牛掰的知识框架,它就是极为硬核且完全自动化的 "LLM Wiki(大模型知识大脑)+ 开源 Agent" 工作流。
实际用下来发现,它不仅彻底终结了 "只收藏不阅读" 的死循环,甚至能把一个陌生领域的调研时间从 5 小时缩短到 20 分钟。
今天不聊虚的概念,直接手把手带你搭建这套能让你效率翻倍的 "全自动 AI 数字大脑"。
这套工作流到底是什么
简单来说,"LLM Wiki" 并不是一个死板的文档管理软件,而是一个 "会自己长大的数字大脑" 范式。
它是前特斯拉 AI 总监 Andrej Karpathy 提出的一种知识管理模式。核心原理很精妙:传统方式下,你每次问 AI 问题,它都得重新读一遍你的原始资料,就像每次运行程序都要重新编译源代码一样。而 LLM Wiki 的做法是,让 AI 把原始资料一次性 "编译" 成一个结构化、持久维护的知识库,以后只查这个编译后的 "产物"。
也就是说你平时收藏的笔记只是粗坯,经过整理后成为精华。
这套工作流的底层核心是 "输入 ➜ 智能加工 ➜ WIKI 输出"。
这个整理过程不需要人来处理,借助于 AI 智能体,由 AI 自动生成的——包含摘要、概念解释、交叉引用和反向链接。
你只需要把 "LLM Wiki" 这个指导文档复制粘贴给任何 AI 智能体(比如 Openclaw, Hermes),跟智能体一步步交互把整个环境和工作流程搭建起来。
当然我们不需要从 0 开始建立 LLM WiKi,社区已经很多人做好了开箱即用的版本,本文中使用 obsidian-wiki 这个框架,它是基于 obsidian 和 AI 来实现 LLM WiKi 的。
这套工作流的逻辑是:你只需把看到的优质文章、长篇 PDF 报告或技术邮件,一键丢进你的 "大模型知识库仓储"。后台的开源 Agent 就会自动触发,完成深度清洗、结构化标签化、交叉知识关联,最终形成一个专属于你的、可随时语义搜索并自动生成综述的 "WIKI 大脑"。
实际工作效果
用实际案例来演示一下。
比如我最近把一篇关于 RAG 系统中「问题解析(Question Parsing)」的深度技术文章扔给 Hermes,让它整理到我的 WiKi,Hermes 一顿操作猛如虎,最后它给我输出结果如下:
📥 导入源文件
《RAG 问题也需要解析:将用户的字符串转化为检索和生成的要点》》
来源:TowardsDataScience · 2026-06-17
📝 新建 Wiki 页面(5 页)
🔗 知识关联
五个页面之间已建立 双向 wikilink 和类型化关系(derived_from、uses、related_to),在 Obsidian 图谱视图中可看到它们互相关联。
📋 已更新的索引文件
✅
index.md— 新增 5 个页面条目✅
log.md— 记录本次导入操作✅
hot.md— 更新最近活动与关键要点✅
.manifest.json— 记录源文件哈希,下次导入将自动跳过未修改文件
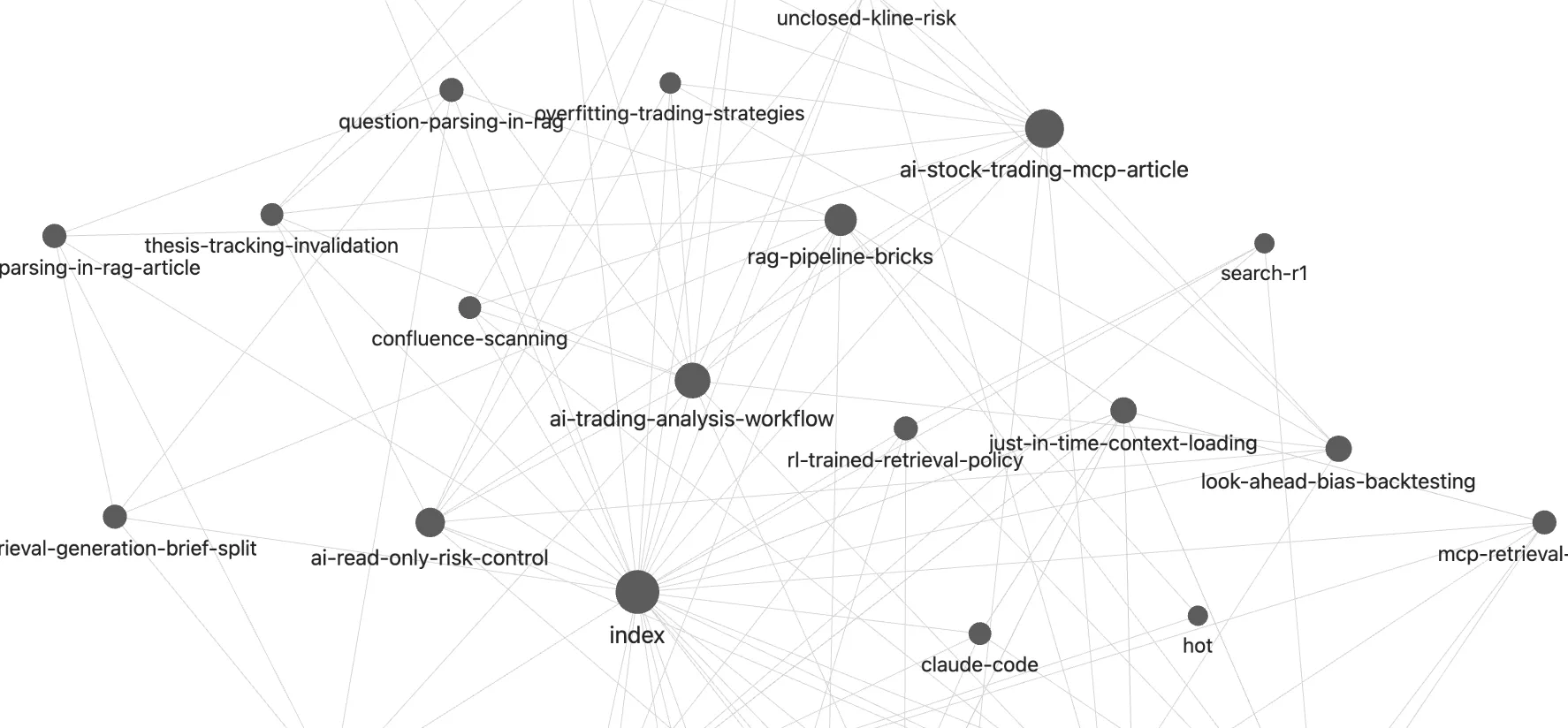
然后我用 obsidian 打开这个 wiki 仓库,可以看到这一篇文章已整理出 5 个页面,其中有 4 个概念,分别是 "RAG 中的问题解析"、"检索和生成阶段拆分"、"否定指令嵌入失败"、"RAG 流水线砖块",还有一个是引用页,也就是原文参考,但它并不是简单地把原文复制进来,而是经过总结的概要。
这样一整篇文章的精华就摘取和提炼出来了,无用和低价值的信息被过滤掉了。这样一个知识库无论对于你的学习还是 AI 的引用,效率都会大大提升。
更妙的是,这几篇笔记互相之间已经关联好了,假如我之后再扔进去 RAG 方面的文章,AI 还会持续回顾和更新原有的知识。
当每个知识节点都互相关联起来,它的价值只会越滚越大。
实际用下来发现,当你积累了 20 篇以上的行业资料后,这个 WIKI 展现出了恐怖的威力——你可以直接对它提问:
"结合我上周收藏的开源 Agent 项目,分析一下最新的 OpenRouter 视频生成 API 可以怎么融入我们的自动化工作流?"
它会立刻调取库内关联知识,直接吐出一份现成的可行性报告。
怎么用?3 步打造你的全自动研究大脑
首先执行以下命令安装 obsidian-wiki,并指定你的 wiki 仓库路径:
pip install obsidian-wiki
obsidian-wiki setup --vault /path/to/your/digital/brain
obsidian-wiki 会安装技能到所有常用的 AI 中,如 openclaw, hermes, claude, codex 等。
obsidian-wiki 只是赋与了 AI 打造 wiki 的技能,如果要让 AI 更好的操作 obsidian,还建议安装 obsidian 的技能,这一步是可选的,用以下命令安装:
npx skills add kepano/obsidian-skills
建议把其中 5 个技能都装上,同样的它也会把技能安装到所有常用 AI 中。
安装完成后,跟你的 Hermes 说,帮我设置我的 wiki,它就会开始初始化和构造了。
参考链接:
Obisdian-WiKi: https://github.com/ar9av/obsidian-wiki
Obsidian-skills: https://github.com/kepano/obsidian-skills




评论 (0)
还没有评论,来说两句吧!