LangGraph 介绍

现在,让我们探索 LangGraph,这是一个功能强大的库,它为构建复杂的多智能体系统提供了结构化的流程。
LangGraph 是建立在 LangChain 之上的一个库,它允许你使用大型语言模型(LLMs)创建具有状态的多智能体应用。它提供了一种结构化的方法,将链条组合成图,管理多个 LLM 调用之间的状态,并通过条件路由构建复杂的流程。
理解 LangGraph 的基础知识
在开始实现之前,让我们先了解一些 LangGraph 中的关键概念:
- 状态 :你在图中不同步骤之间持续存在的信息
- 节点 :处理状态并返回新状态的函数
- 边 :定义状态在节点之间流动的方式
- Graph :通过边连接节点的整体工作流程
这种结构化方法使得代理之间能够进行更复杂的交互,包括条件路由、反馈循环和持久记忆。
LangGraph 工作流
让我们来看看一个基本的 LangGraph 是如何工作的:
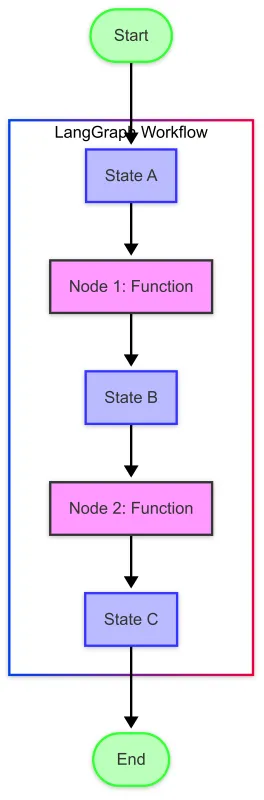
此图展示了关键概念:
- State (蓝色框):包含在图中流动的数据
- Nodes (紫色框):处理状态并生成新状态的函数
- 边 (箭头):定义从一个节点到下一个节点的流程
- 入口/出口点 (绿色椭圆):工作流程的开始和结束位置
环境设置
首先,让我们确保所有必要的包都已安装。如果你第一次运行这段代码,你需要安装所需的包。
Install required packages
# Install required packages with latest versions
!pip install langchain langchain-openai langgraph python-dotenv
现在,让我们设置环境变量。我们需要一个 OpenAI 的 API 密钥来使用他们的模型。在与该笔记本相同的目录下,创建一个 .env 文件,并将你的 OpenAI API 密钥放入其中:
OPENAI_API_KEY=your_api_key_here
# Load environment variables from .env file
import os
from dotenv import load_dotenv
load_dotenv() # Load API keys from .env file
# Verify that the API key is loaded
if os.getenv("OPENAI_API_KEY") is None:
print("Warning: OPENAI_API_KEY not found in environment variables.")
else:
print("OPENAI_API_KEY found in environment variables.")
Importing Required Libraries
现在,让我们导入我们多智能体系统所需的库:
# Import necessary libraries
from typing import Dict, List, TypedDict, Annotated, Sequence, Any, Optional, Literal, Union
import json
# Modern imports for langchain and langgraph
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage, BaseMessage
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, END
创建一个简单的 LLM 辅助函数
在深入探讨多智能体系统之前,我们先创建一个简单的辅助函数来与 LLM 进行交互。这将帮助我们理解 LangGraph 的基本构建模块。
def ask_llm(prompt, model="gpt-4o", temperature=0.7):
"""A simple function to get a response from an LLM."""
# Create a ChatOpenAI instance
llm = ChatOpenAI(model=model, temperature=temperature)
# Create a message with the prompt
messages = [HumanMessage(content=prompt)]
# Get a response from the LLM
response = llm.invoke(messages)
# Return the content of the response
return response.content
# Let's test our function
response = ask_llm("What is LangGraph and how does it relate to LangChain?")
print(response)
Response output:
LangGraph 是一个开源库,专为构建和管理使用大型语言模型(LLMs)的复杂应用程序而设计。它是一个框架,提供工具和组件来创建、定制和执行涉及 LLMs 的工作流,使这些模型更容易集成到各种应用程序中。LangGraph 与 LangChain 密切相关,可以认为它是 LangChain 的扩展或互补工具集。 LangChain 是另一个专门用于开发基于 LLMs 应用程序的框架,专注于将不同的组件或任务串联起来,以创建更复杂的流程。LangGraph 在 LangChain 的基础上,通过提供额外的功能和更结构化的方式来定义和管理基于 LLM 的应用程序。 本质上,虽然 LangChain 专注于语言模型驱动任务的链接,但 LangGraph 提供了一个更全面的框架,包括基于图的执行流程、对任务的增强控制以及对不同组件之间交互的改进管理。借助这些工具,可以简化利用 LLMs 能力开发和部署复杂应用的过程。
让我们创建一个非常简单的图,只包含一个代理来理解这些概念:
# Define the state type
class SimpleState(TypedDict):
messages: List[BaseMessage] # The conversation history
next: str # Where to go next in the graph
# Define a simple agent node
def simple_agent(state: SimpleState) -> SimpleState:
"""A simple agent that responds to the last message."""
messages = state["messages"]
llm = ChatOpenAI(model="gpt-4o", temperature=0.7)
response = llm.invoke(messages)
return {"messages": messages + [response], "next": "output"}
# Define an output node
def output(state: SimpleState):
"""Return the final state. This marks the end of the workflow."""
return {"messages": state["messages"], "next": END}
# Build the graph
def build_simple_graph():
"""Build a simple LangGraph workflow."""
# Create a new graph
workflow = StateGraph(SimpleState)
# Add nodes
workflow.add_node("agent", simple_agent)
workflow.add_node("output", output)
# Add edges
workflow.add_edge("agent", "output")
# Set the entry point
workflow.set_entry_point("agent")
# Compile the graph
return workflow.compile()
现在,让我们运行我们的简单图:
# Create the graph
simple_graph = build_simple_graph()
# Initialize the state with a test message
initial_state = {
"messages": [HumanMessage(content="Explain what a multi-agent system is in simple terms.")],
"next": ""
}
# Run the graph
result = simple_graph.invoke(initial_state)
# Print the conversation
for message in result["messages"]:
if isinstance(message, HumanMessage):
print(f"Human: {message.content}")
elif isinstance(message, AIMessage):
print(f"AI: {message.content}")
Output:
人类:用简单的话解释什么是多智能体系统。
AI:多智能体系统是由多个独立的“智能体”组成的,它们之间可以相互交互。可以将每个智能体看作一个具有自己决策能力的个体,就像人们可以独立思考和行动一样。这些智能体协作或竞争,以实现特定目标或完成任务。
简单来说,想象一下一群清洁房屋的机器人。每个机器人都是一个智能体。一个负责吸尘,另一个负责擦拭家具,还有一个负责倒垃圾。它们各自独立工作,但会相互沟通和协调,以确保整个房屋高效地被清洁。这就是多智能体系统的核心:多个实体协同工作,通常以协调的方式,来执行复杂任务或解决问题。
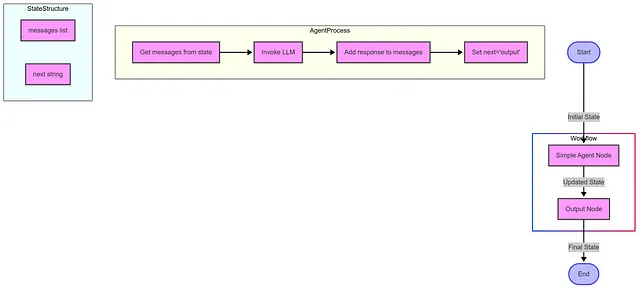
This diagram shows:
- 从开始 → 代理 → 输出 → 结束的整体流程
- 展示 simple_agent 函数内部步骤的代理处理子图
- 显示 SimpleState TypedDict 组件的 State 子图
- 用颜色编码的节点来区分不同类型的组件
工作流程从一个包含消息和下一步字段的初始状态开始,通过代理节点对其进行处理,代理节点使用 LLM 添加响应,然后将其传递给输出节点,输出节点返回最终状态,从而结束整个工作流程。
现在,让我们理解刚才发生了什么:
- 我们定义了一个状态模式(
SimpleState),包含我们希望跟踪的字段。 - 我们为代理和输出函数创建了节点。
- 我们通过边将这些节点连接起来,以定义信息的流动。
- 我们设置了一个入口点并编译了图。
- 我们用一条人类消息初始化了状态并运行了图。
这个简单的例子展示了 LangGraph 的基本概念。在实际应用中,你可以创建更加复杂的图,包含多个节点和条件边。
What’s Next
下一步,我们将构建我们的第一个专用代理:研究代理。我们将深入了解代理设计模式,学习如何定义代理的角色和能力,并了解如何有效地让代理执行研究任务。
创建一个专业研究人员代理
在上一步中,我们搭建了环境并创建了一个包含单个代理的简单图。现在,我们将构建我们协作研究助手系统中的第一个专用代理:研究者代理。
在这一步中,我们将专注于构建研究者代理——负责收集和分析信息的组件。
What is a Researcher Agent?
研究代理是一种设计用于深入探讨主题并提供全面、结构良好的信息的 AI 系统。它在我们的多代理系统中充当信息收集组件,具备以下能力:
- 深入理解研究查询
- 全面收集相关信息
- 以结构化、易于访问的格式整理研究成果
- 客观准确地呈现信息
- 识别现有信息中的局限性和不足之处
使用 LangGraph 构建现代研究代理
LangGraph 和 LangChain 的最新版本提供了改进的代理构建方法。让我们探索如何使用这些现代工具创建一个研究代理。
步骤 1:设置环境
首先,我们需要导入必要的库。请注意 LangChain 和 LangGraph 的现代导入路径:
from typing import Dict, List, TypedDict, Any, Optional
import json
import os
from dotenv import load_dotenv
# Modern imports for langchain and langgraph
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage, BaseMessage
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, END
# Load environment variables
load_dotenv()
步骤 2:定义研究者的角色
一个清晰的系统提示对于塑造代理的行为至关重要:
RESEARCHER_SYSTEM_PROMPT = """
You are a skilled research agent tasked with gathering comprehensive information on a given topic.
Your responsibilities include:
1. Analyzing the research query to understand what information is needed
2. Conducting thorough research to collect relevant facts, data, and perspectives
3. Organizing information in a clear, structured format
4. Ensuring accuracy and objectivity in your findings
5. Citing sources or noting where information might need verification
6. Identifying potential gaps in the information
Present your findings in a well-structured format with clear sections and bullet points where appropriate.
Your goal is to provide comprehensive, accurate, and useful information that fully addresses the research query.
"""
步骤3:创建研究者函数
现在我们将实现研究者代理作为函数:
def create_researcher_agent(model="gpt-4o", temperature=0.7):
"""Create a researcher agent using the specified LLM."""
# Initialize the model
llm = ChatOpenAI(model=model, temperature=temperature)
def researcher_function(messages):
"""Function that processes messages and returns a response from the researcher agent."""
# Add the system prompt if it's not already there
if not messages or not isinstance(messages[0], SystemMessage) or messages[0].content != RESEARCHER_SYSTEM_PROMPT:
messages = [SystemMessage(content=RESEARCHER_SYSTEM_PROMPT)] + (messages if isinstance(messages, list) else [])
# Get response from the LLM
response = llm.invoke(messages)
return response
return researcher_function
与 LangGraph 集成:现代方法
最新版本的 LangGraph 使用 TypedDict 进行状态管理,提供了更好的类型安全性和更清晰的状态结构:
# Define the state type for our research workflow
class ResearchState(TypedDict):
"""Type definition for our research workflow state."""
messages: List[BaseMessage] # The conversation history
query: str # The research query
research: Optional[str] # The research findings
next: Optional[str] # Where to go next in the graph
Creating a Researcher Node
接下来,我们实现一个用于我们的 LangGraph 工作流的节点:
def researcher_node(state: ResearchState) -> ResearchState:
"""A node in our graph that performs research on the query."""
# Get the query from the state
query = state["query"]
# Create a message specifically for the researcher
research_message = HumanMessage(content=f"Please research the following topic thoroughly: {query}")
# Get the researcher agent
researcher = create_researcher_agent()
# Get response from the researcher agent
response = researcher([research_message])
# Update the state with the research findings
new_messages = state["messages"] + [research_message, response]
# Return the updated state
return {
**state,
"messages": new_messages,
"research": response.content,
"next": "output" # In a multi-agent system, this would go to the next agent
}
构建研究工作流
现在我们可以构建一个完整的 LangGraph 工作流:
def build_research_graph():
"""Build a simple research workflow using LangGraph."""
# Create a new graph with our state type
workflow = StateGraph(ResearchState)
# Add nodes
workflow.add_node("researcher", researcher_node)
workflow.add_node("output", output_node)
# Add edges
workflow.add_edge("researcher", "output")
# Set the entry point
workflow.set_entry_point("researcher")
# Compile the graph
return workflow.compile()
以下是我们的工作流的可视化表示:
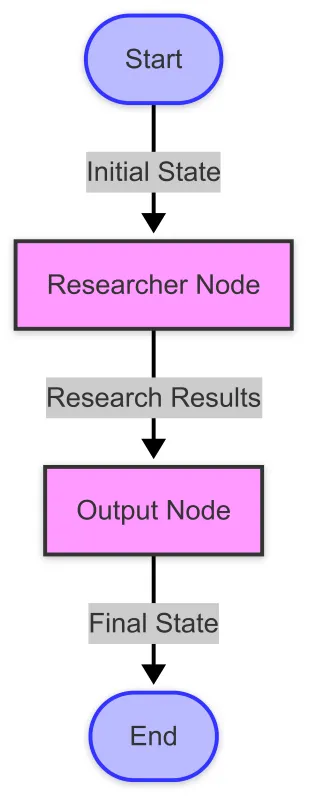
增强研究代理的结构化输出
为了更好地与其他代理集成,我们可以增强研究代理以提供结构化输出:
ENHANCED_RESEARCHER_PROMPT = """
You are a skilled research agent tasked with gathering comprehensive information on a given topic.
Your responsibilities include:
1. Analyzing the research query to understand what information is needed
2. Conducting thorough research to collect relevant facts, data, and perspectives
3. Organizing information in a clear, structured format
4. Ensuring accuracy and objectivity in your findings
5. Citing sources or noting where information might need verification
6. Identifying potential gaps in the information
Present your findings in the following structured format:
SUMMARY: A brief overview of your findings (2-3 sentences)
KEY POINTS:
- Point 1
- Point 2
- Point 3
DETAILED FINDINGS:
1. [Topic Area 1]
- Details and explanations
- Supporting evidence
- Different perspectives if applicable
2. [Topic Area 2]
- Details and explanations
- Supporting evidence
- Different perspectives if applicable
GAPS AND LIMITATIONS:
- Identify any areas where information might be incomplete
- Note any contradictions or areas of debate
- Suggest additional research that might be needed
Your goal is to provide comprehensive, accurate, and useful information that fully addresses the research query.
"""
这种结构化的格式使得后续的代理(如评论者和撰写者)能够更方便地处理和扩展研究者的发现。
更稳健的研究工作流程
借助我们增强的科研代理,我们可以创建一个更强大的工作流程:
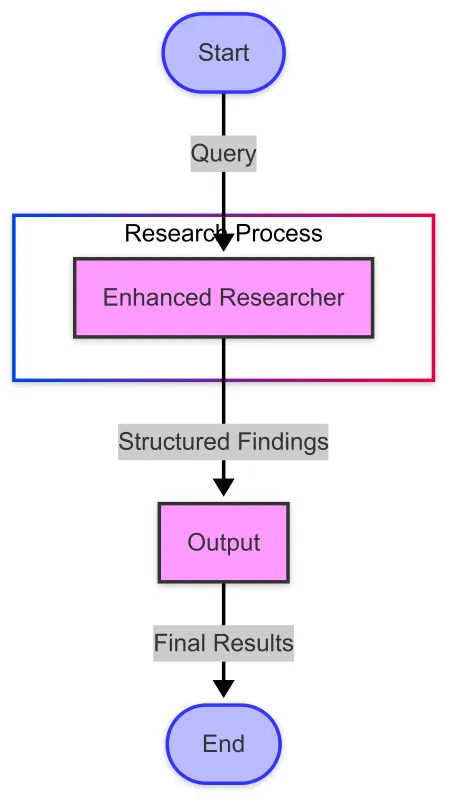
我们通过一种专用的状态类型来实现这个工作流程:
class EnhancedResearchState(TypedDict):
"""Enhanced type definition for our research workflow state."""
messages: List[BaseMessage]
query: str
structured_research: Optional[str]
next: Optional[str]
研究人员代理实例:一个示例查询
我们来看看我们的增强型研究代理如何处理一个复杂查询:
查询:“可再生能源技术的最新进展有哪些?”
Response (structured format):
摘要:可再生能源技术的最新进展包括太阳能电池效率的显著提升、创新的风力涡轮机设计、增强的能源存储解决方案、绿色氢能生产的突破以及先进生物燃料的发展。
KEY POINTS:
钙钛矿-硅 tandem 电池的光伏技术已实现创纪录的效率,超过 30%的效率
浮动式海上风力涡轮机正在拓展在更深水域的部署可能性
大规模电池储能成本大幅下降,而能量密度却有所提高
通过电解生产绿氢已经变得更加高效且经济可行
- 非粮食生物质来源的先进生物燃料正接近商业化可行性
DETAILED FINDINGS:
1. Solar Energy Advancements
— 钙钛矿太阳能电池性能迅速提升,实验室效率超过25%
— 钙钛矿-硅叠层太阳能电池效率达到31.25%,接近理论极限
— 双面太阳能板可以从两侧捕捉光线,使发电量提高5%-30%
— 建筑一体化光伏(BIPV)随着透明太阳能电池在窗户上的应用而取得进展
— 将农业与太阳能生产结合的农光互补系统已显示出 promising results(有前景的结果)
2. Wind Energy Innovations
— 更大的风力涡轮机,其叶片长度超过100米,提高了容量系数
— 浮式海上风电平台可在水深60米以上的海域部署
— 空中风能系统(基于风筝和无人机)处于高级测试阶段
— 使用摆动技术的无叶片风力涡轮机减少了对野生动物的影响和维护成本
—— 数字孪生技术与人工智能提升预测性维护和产出优化
[为简洁起见,省略了附加部分]
GAPS AND LIMITATIONS:
尽管技术不断进步,长时储能(10小时以上)仍然是一个重大挑战
- 提到的大多数突破性技术目前仍处于从实验室向商业部署扩展的阶段
新兴技术的成本比较往往缺乏标准化的度量标准
一些较新的技术(如某些用于制造磁体的稀有金属采矿)的环境影响需要进一步研究
- 技术采用和政策支持的地区差异导致了发展进程的不平衡
现代方法的优势
使用 LangGraph 构建研究代理的现代方法具有以下优势:
- 类型安全 :TypedDict 提供了更好的类型检查和文档说明
- 结构化状态 :明确定义的状态结构提高了可维护性
- 模块化设计 :函数和组件可以轻松地复用和测试
- 现代 API:使用最新的 LangChain 和 LangGraph API 可确保兼容性
下一步:构建完整的多智能体系统
研究代理只是构建全面多代理系统的第一步。在未来的文章中,我们将探讨:
- 构建一个评论代理来评估和质疑研究者的发现
- 创建一个撰写代理,将信息综合成连贯的内容
- 实现一个协调代理来管理代理之间的工作流程
- 开发更动态的智能体交互的高级路由逻辑
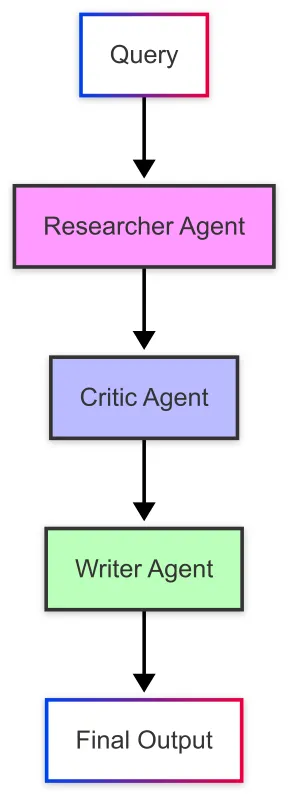
使用 LangGraph 构建现代研究代理为多代理系统提供了强大的基础。通过利用最新的 API 和结构化的方法进行代理开发,我们可以创建更加高效、可维护和强大的 AI 系统,这些系统协作解决复杂问题。
我们构建的研究代理展示了如何设计专门的代理来在更大的系统中履行特定角色——收集和整理信息,然后由工作流中的其他代理进行评估、优化和呈现。
在继续探索多智能体系统的过程中,我们将看到这些专用组件如何协同工作,创建超越单一模型所能单独实现的 AI 解决方案。
Adding a Critic Agent
在之前的步骤中,我们已经搭建了环境并创建了一个研究代理。现在,我们将向我们的协作研究助手系统中添加第二个专用代理:批评代理。
The Concept of a Critic Agent
批评代理被设计用来评估、挑战和改进其他代理的工作。正如人类工作受益于同行评审和建设性批评一样,AI 输出也可以通过专门的评估得到显著提升。
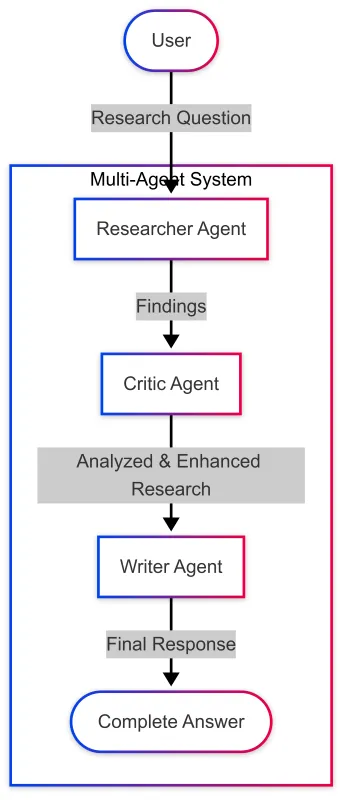
批评代理在多代理工作流程中发挥着关键作用:
- 质量保证 :识别研究中的不准确之处、遗漏或缺陷
- 偏差检测 :突出显示所提供信息中的潜在偏差
- 完整性检查 :确保主题的各个方面得到充分覆盖
- 不同视角 :介绍不同的观点或解释
- 建设性反馈 :提供可操作的改进建议
使用 LangGraph 的现代实现
LangGraph 和 LangChain 的最新版本提供了构建更强大且易于维护的多智能体系统的有力工具。让我们探索如何利用这些现代框架实现一个批评者智能体。
Core Components
我们的实现关注三个关键要素:
- 类型安全 :使用
TypedDict进行状态管理 - 结构化输出 : 通过结构化 JSON 反馈增强批评者
- 模块化设计 : 创建可重用的代理功能
批评者的系统提示
我们批评者代理的基础是一个精心设计的系统提示,用于确立其角色和职责:
CRITIC_SYSTEM_PROMPT = """
You are a Critic Agent, part of a collaborative research assistant system. Your role is to evaluate
and challenge information provided by the Researcher Agent to ensure accuracy, completeness, and objectivity.
Your responsibilities include:
1. Analyzing research findings for accuracy, completeness, and potential biases
2. Identifying gaps in the information or logical inconsistencies
3. Asking important questions that might have been overlooked
4. Suggesting improvements or alternative perspectives
5. Ensuring that the final information is balanced and well-rounded
Be constructive in your criticism. Your goal is not to dismiss the researcher's work, but to strengthen it.
Format your feedback in a clear, organized manner, highlighting specific points that need attention.
Remember, your ultimate goal is to ensure that the final research output is of the highest quality possible.
"""
Modern State Management
LangGraph 最近版本的一个重要改进是通过 TypedDict 实现了更好的状态管理:
class CollaborativeResearchState(TypedDict):
"""State type for our collaborative research assistant."""
messages: List[BaseMessage] # The conversation history
next: Optional[str] # Where to go next in the graph
这种方法提供了清晰的类型提示,使代码更易于维护。
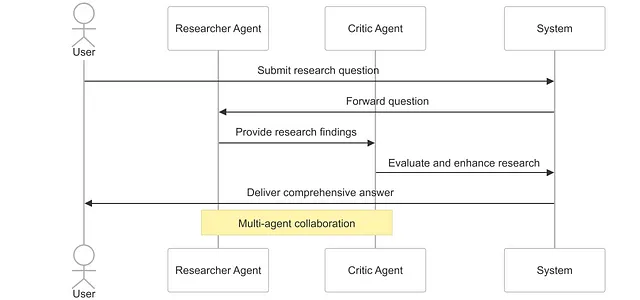
流程:研究者 → 批评者
让我们可视化研究者和批评者代理之间信息的基本流动:

我们的 LangGraph 实现使用现代语法定义了这个工作流程:
def build_collaborative_research_assistant():
"""Build a collaborative research assistant with researcher and critic agents."""
# Create a new graph with our state type
workflow = StateGraph(CollaborativeResearchState)
# Add nodes
workflow.add_node("researcher", researcher_node)
workflow.add_node("critic", critic_node)
workflow.add_node("output", output_node)
# Add edges
workflow.add_edge("researcher", "critic")
workflow.add_edge("critic", "output")
# Set the entry point
workflow.set_entry_point("researcher")
# Compile the graph
return workflow.compile()
通过结构化输出增强批评者
为了使我们的评论者代理对后续流程更有用,我们可以增强它,使其以 JSON 格式提供结构化的反馈。这使得其他代理(如写作代理)更容易处理并整合这些批评。
以下是实现结构化评论的方法:
class CriticEvaluation(BaseModel):
"""Structured format for critic evaluations."""
quality_score: int = Field(description="Overall quality score from 1-10")
strengths: List[str] = Field(description="Key strengths of the research")
areas_for_improvement: List[str] = Field(description="Areas that need improvement")
missing_information: List[str] = Field(description="Important information that was not included")
bias_assessment: str = Field(description="Assessment of potential biases in the research")
additional_questions: List[str] = Field(description="Questions that should be addressed")
这种结构化方法使我们能够构建一个更稳健的工作流程:
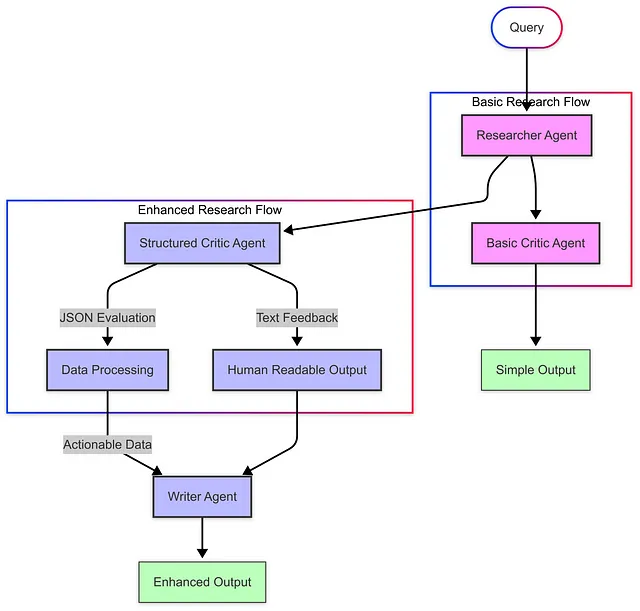
完整的多智能体研究流程
当我们把所有内容整合起来,我们的多智能体系统遵循以下流程:
- 用户输入 :用户提交一个研究问题
- 研究阶段 :研究代理收集并整理信息
- 批判阶段 :批判代理评估研究的质量和完整性
- 结构化反馈 :系统提供有条理、可操作的批评
- 最终输出 :综合的研究与批评提供了全面的回应
现代方法的优势
使用最新 LangGraph 和 LangChain API 的现代实现提供了多项优势:
- 类型安全 :正确类型的 state 可以减少错误并提高代码的可维护性
- 结构化输出 :JSON 格式的批评可以更方便地与其他组件集成
- 更好的可维护性 :通过模块化代理设计实现职责分离
- 可视化支持 :内置工具用于工作流可视化和理解
通过在我们的多智能体系统中添加一个批评者智能体,我们创建了一个强大的监督和制衡机制,从而提升人工智能生成研究的质量、准确性和完整性。这种方法模拟了人类协作过程,其中同行评审和建设性批评能够带来更好的成果。
结构化批评方法还为我们在多智能体旅程中的下一步奠定了基础:添加一个能够将研究和批评综合成连贯、精心撰写的最终回复的撰写智能体。
在下一节中,我们将探讨如何构建这个 Writer Agent,并完成我们的多智能体研究助手系统。
The Writer Agent
在本文的前几个步骤中,我们探讨了如何构建一个协作型研究助手,其中包括专门化的代理:一个研究代理用于收集信息,一个批评代理用于评估和挑战这些信息。现在,是时候添加第三个关键组件:一个撰写代理,它将把这些信息综合成一个条理清晰、写得好的回答。 本节探讨如何实现一个 Writer Agent,它能够综合信息并生成连贯、全面的输出——从而创建一个完整的协作研究流程,模拟由研究人员、编辑和撰写者组成的人类团队。
The Concept of a Writer Agent
Writer Agent 在多智能体系统中充当最终的沟通者,将原始研究和深入分析转化为精炼、连贯的内容,以优化人类的阅读体验。
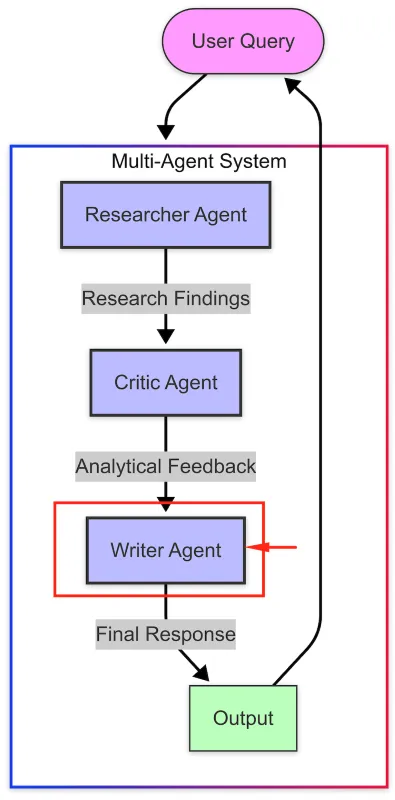
Writer Agent 在工作流程中承担着几个关键功能:
- 信息综合 :结合研究者的研究成果和评论者的评估意见
- 组织 :以逻辑化、易于访问的方式为最终用户整理信息
- 风格适应 :以清晰、吸引人的语言呈现信息,适合特定的语境
- 视角整合:平衡不同观点以形成全面的回应
- 清晰度提升 :在不牺牲准确性的前提下简化复杂概念
使用 LangGraph 的现代实现
LangGraph 和 LangChain 的最新版本提供了构建集成多代理系统的复杂工具。让我们探索如何使用这些现代框架实现一个 Writer Agent。
写作代理的系统提示
我们写作代理的基础是一个精心设计的系统提示:
WRITER_SYSTEM_PROMPT = """
You are a Writer Agent, part of a collaborative research assistant system. Your role is to synthesize
information from the Researcher Agent and feedback from the Critic Agent into a coherent, well-written response.
Your responsibilities include:
1. Analyzing the information provided by the researcher and the feedback from the critic
2. Organizing the information in a logical, easy-to-understand structure
3. Presenting the information in a clear, engaging writing style
4. Balancing different perspectives and ensuring objectivity
5. Creating a final response that is comprehensive, accurate, and well-written
Format your response in a clear, organized manner with appropriate headings, paragraphs, and bullet points.
Use simple language to explain complex concepts, and provide examples where helpful.
Remember, your goal is to create a final response that effectively communicates the information to the user.
"""
现代状态管理与节点实现
最近版本的 LangGraph 一个关键改进是使用 TypedDict 进行状态管理,提供了更好的代码组织和类型安全:
class CollaborativeResearchState(TypedDict):
"""State type for our collaborative research assistant."""
messages: List[BaseMessage] # The conversation history
next: Optional[str] # Where to go next in the graph
Writer 节点的实现采用了一种简洁、功能性的方法:
def writer_node(state: CollaborativeResearchState) -> CollaborativeResearchState:
"""Node function for the writer agent."""
# Extract messages from the state
messages = state["messages"]
# Create writer messages with the system prompt
writer_messages = [SystemMessage(content=WRITER_SYSTEM_PROMPT)] + messages
# Initialize the LLM with a balance of creativity and accuracy
llm = ChatOpenAI(model="gpt-4o", temperature=0.6)
# Get the writer's response
response = llm.invoke(writer_messages)
# Return the updated state
return {
"messages": messages + [response],
"next": "output"
}
完整的多代理工作流程
当我们把写作代理与我们的研究代理和批评代理集成在一起时,我们创建了一个复杂的流程,模拟专业研究和写作团队的工作方式:
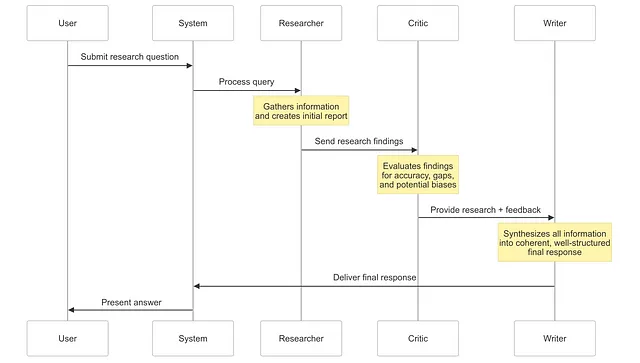
这种工作流程在 LangGraph 中的实现非常清晰且易于维护:
def build_complete_research_assistant():
"""Build a complete research assistant with researcher, critic, and writer agents."""
# Create a new graph with our state type
workflow = StateGraph(CollaborativeResearchState)
# Add nodes
workflow.add_node("researcher", researcher_node)
workflow.add_node("critic", critic_node)
workflow.add_node("writer", writer_node)
workflow.add_node("output", output_node)
# Add edges
workflow.add_edge("researcher", "critic")
workflow.add_edge("critic", "writer")
workflow.add_edge("writer", "output")
# Set the entry point
workflow.set_entry_point("researcher")
# Compile the graph
return workflow.compile()
高级应用的增强功能
对于更复杂的应用,我们可以通过增强功能来提升 Writer Agent 及其整体工作流程:
Rich Metadata Tracking
我们可以创建一个增强的状态类型,用于跟踪每个代理的贡献元数据:
class EnhancedResearchState(TypedDict):
"""Enhanced state type with metadata for the research process."""
messages: List[BaseMessage] # The conversation history
metadata: Dict[str, Any] # Metadata about each step in the process
next: Optional[str] # Where to go next in the graph
这使我们能够捕获诸如处理时间、令牌数量和模型参数等信息,这些信息对分析和优化非常有价值:
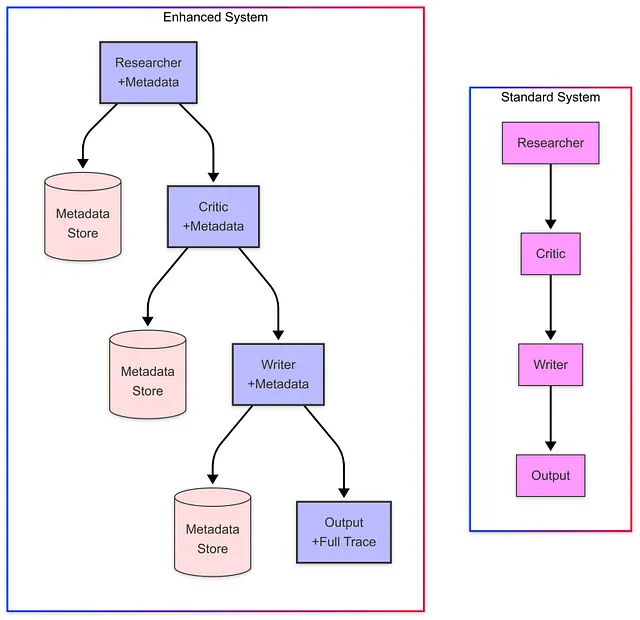
灵活的架构模式
我们构建的三代理结构(研究者 → 批评者 → 写作者)可以适应各种应用需求:
1. Hierarchical Organization:
- 研究团队(多位专业研究人员)→ 编辑 → 写作
2. Parallel Processing:
- 多位研究人员分别负责不同方面 → 评论者逐部分评估 → 写作人综合所有内容
3. Hybrid Structures:
- 一些代理按顺序工作,另一些则并行工作,具体取决于任务
Benefits of the Writer Agent
向您的多代理系统添加一个 Writer 代理可以带来几个关键优势:
- 改进的沟通 :内容以优化人类理解的方式呈现
- 一致性 :写作风格和结构保持一致,即使研究涵盖多样化的主题
- 集成 :各种视角和信息被有机地编织在一起
- 效率 :最终输出可以直接使用,无需额外编辑或重新格式化
- 适应性 :Writer Agent 可以根据上下文和受众调整其风格和结构
通过向我们的系统中添加 Writer Agent,我们完成了一个强大的协作流程,该流程模拟了人类在处理复杂信息任务时的合作方式。系统中的每个代理都有专门的角色:
- 研究代理收集全面信息
- 批评代理( 批评代理 )评估并确保质量
- 写作者代理能有效与终端用户沟通
这种职责分离使每个代理都能在各自的任务上表现出色,同时为整体的协同工作做出贡献。通过使用现代的 LangGraph 和 LangChain 功能,如 TypedDict 进行状态管理,我们构建了一个不仅功能强大,而且易于维护和扩展的系统。
多智能体系统代表了 AI 应用设计的重要进步,突破了单智能体方法的局限性,创造出更加稳健、平衡和有效的解决方案。
The Coordinator Agent
在我们使用 LangGraph 构建复杂多智能体系统的旅程中,我们已经探索了专门用于研究、批评和写作的智能体。现在,让我们关注一个关键组件,它将固定、顺序的工作流程转变为真正动态、智能的解决方案:协调智能体。
多智能体系统中的协调需求
随着多智能体系统复杂性的增加,协调智能体之间的交互变得越来越重要。一个设计良好的协调器可以:
- 分析用户查询以确定最佳工作流程
- 跳过简单请求中的不必要的步骤
- 在需要时启动额外的研究周期
- 确保所有相关专家适当参与
- 根据中间结果调整工作流程
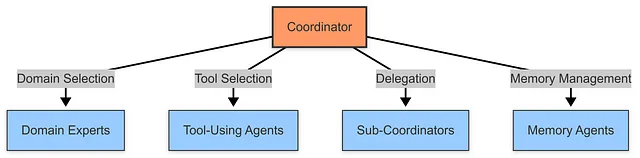
协调者代理架构
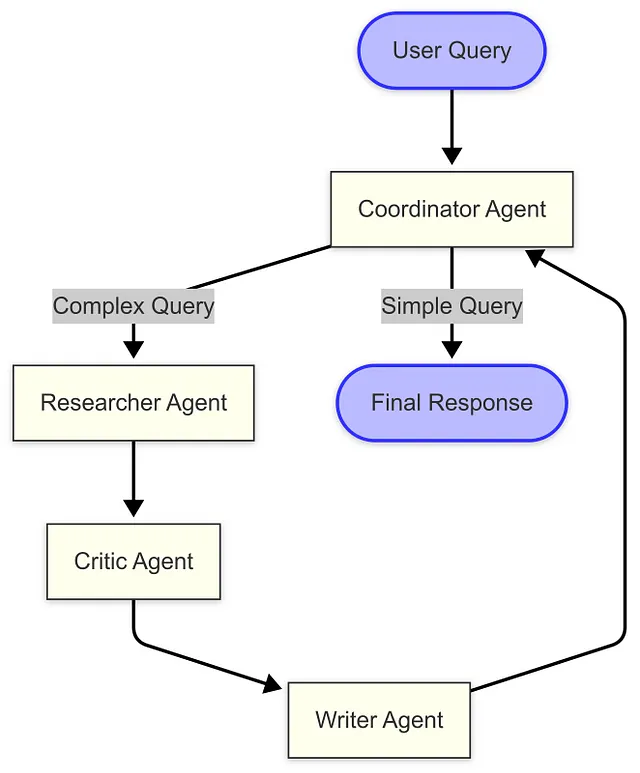
上面的图示展示了我们的动态多代理架构。与以往的实现不同,这些代理以前是在固定顺序中运行的,而该系统使用协调代理来在每个阶段确定最佳路径。对于简单的查询,它可以完全跳过研究过程,而对于复杂的问题,则会协调完整的研究周期。
在现代 LangGraph 中构建协调代理
现代的 LangGraph 提供了实现这种动态架构的强大工具:
def coordinator_node(state: ResearchState) -> ResearchState:
"""Coordinator node that decides the workflow path."""
# Extract messages from the state
messages = state["messages"]
# Create coordinator messages with the system prompt
coordinator_messages = [SystemMessage(content=COORDINATOR_SYSTEM_PROMPT)] + messages
# Initialize the LLM with a lower temperature for consistent decision-making
llm = ChatOpenAI(model="gpt-4o", temperature=0.2)
# Get the coordinator's response
response = llm.invoke(coordinator_messages)
# Parse the JSON response to determine next steps
try:
decision = json.loads(response.content)
next_step = decision.get("next", "researcher") # Default to researcher if not specified
except Exception:
# If there's an error parsing the JSON, default to the researcher
next_step = "researcher"
# Return the updated state
return {"messages": messages, "next": next_step}
我们在实现中的关键改进在于工作流图中使用了条件边:
# Add conditional edges from the coordinator
workflow.add_conditional_edges(
"coordinator",
lambda state: state["next"],
{
"researcher": "researcher",
"done": "output"
}
)
动态决策的实践应用
让我们看看我们的协调者代理的决策过程是怎样的:
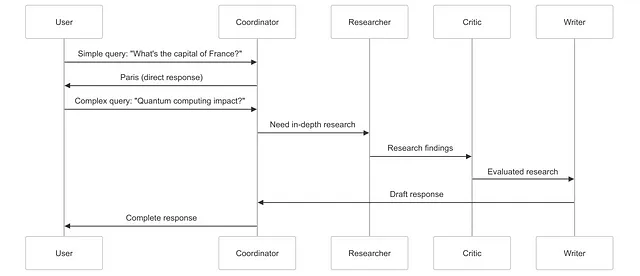
对于简单的事实性问题,协调者可以直接给出答案,避免不必要的工作。对于需要专业知识的复杂主题,它会协调所有专业代理参与完整的调研流程。
对比:静态工作流与动态工作流
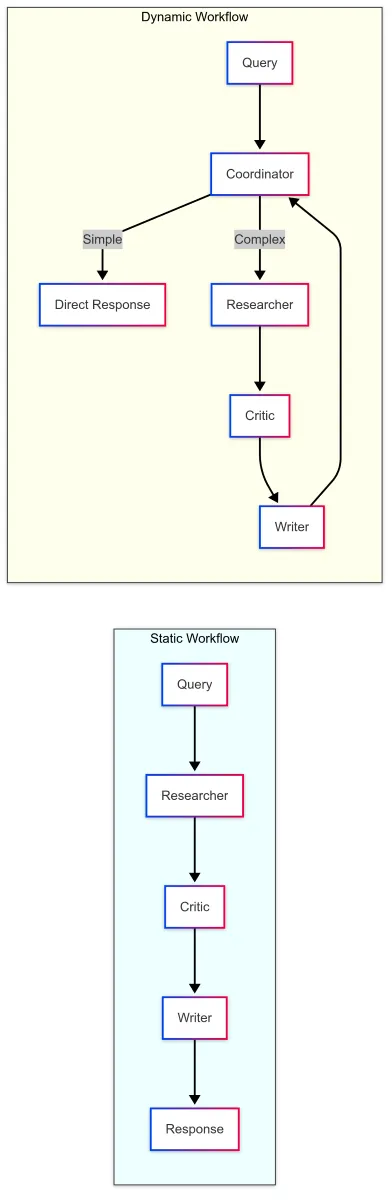
上述比较突显了静态工作流和动态工作流之间的关键区别。使用协调代理的动态方法提供了:
- 效率 :简单查询可立即获得响应
- 适应性 :工作流程根据查询复杂度进行调整
- 智能性 :在关键节点进行决策
- 递归 :在需要时能够回溯进行进一步研究的能力
技术实现细节
我们的实现利用了多个现代 LangGraph 功能:
- 类型字典用于状态管理 :使用
ResearchState进行适当的类型标注 - 条件边 :基于代理决策的动态路由
- 结构化输出 :使用 JSON 格式进行推理和下一步操作
- 错误处理 :健壮的解析并带有回退机制
- LLM 集成 :我通过这些示例使用 GPT-4o。
这种方法提供了一种干净、易于维护和扩展的架构,可以适应各种应用场景。
扩展协调者模式
协调者模式可以以多种方式进行扩展:
构建动态多智能体系统
在我们的协调代理实现之后,我们现在可以将系统从一个固定、顺序的流程转变为一个动态流程,由协调代理决定采取哪条路径:
def build_dynamic_research_assistant():
"""Build a dynamic research assistant with a coordinator agent managing the workflow."""
# Create a new graph
workflow = Graph()
# Add nodes
workflow.add_node("coordinator", coordinator_agent)
workflow.add_node("researcher", researcher_agent)
workflow.add_node("critic", critic_agent)
workflow.add_node("writer", writer_agent)
workflow.add_node("output", output)
# Add conditional edges from the coordinator
workflow.add_conditional_edges(
"coordinator",
lambda state: state["next"],
{
"researcher": "researcher",
"done": "output"
}
)
# Add the rest of the edges
workflow.add_edge("researcher", "critic")
workflow.add_edge("critic", "writer")
workflow.add_edge("writer", "coordinator")
workflow.add_edge("output", END)
# Set the entry point
workflow.set_entry_point("coordinator")
# Compile the graph
return workflow.compile()
这个图创建了一个动态的工作流程,其中:
- 协调代理会分析用户的查询,并决定是调动研究团队还是直接给出回答
- 如果需要进行研究,查询将通过我们的专用代理流程:研究者 → 批评者 → 写作者
- 作者完成工作后,控制权会返回给协调者,协调者可以选择将响应发送给用户,或者启动进一步的研究
- 这形成一个循环,使复杂查询可以通过多次研究、批判和写作的迭代过程得到完善
Visual Workflow Diagrams
动态多智能体系统架构
以下是我们的动态多代理系统中协调代理的可视化表示:
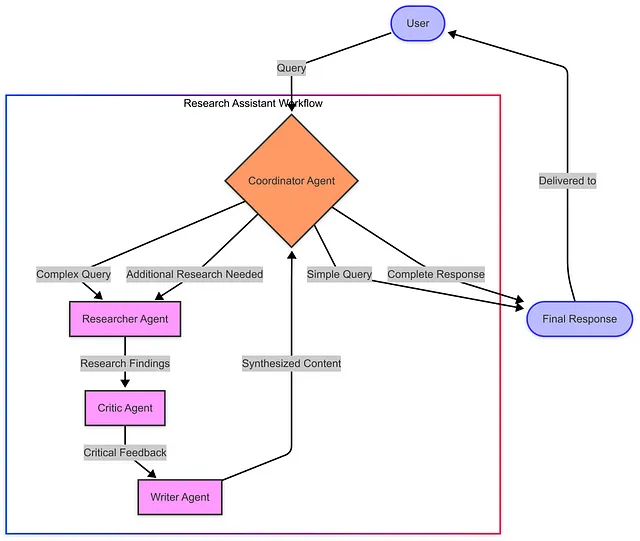
该图展示了我们系统动态的特性:
- 协调代理首先接收所有用户查询
- 对于简单的查询,协调器可以直接提供响应
- 对于复杂查询,协调员会将它们路由到我们的专家代理
- 作者代理生成回复后,协调者会对其进行审阅
- 协调员可以选择交付最终响应或要求进行额外研究
- 这创建了一个反馈循环,可以处理复杂、多步骤的查询
不同查询类型的决策流程
我们也可以可视化不同类型的查询在系统中的流动情况:
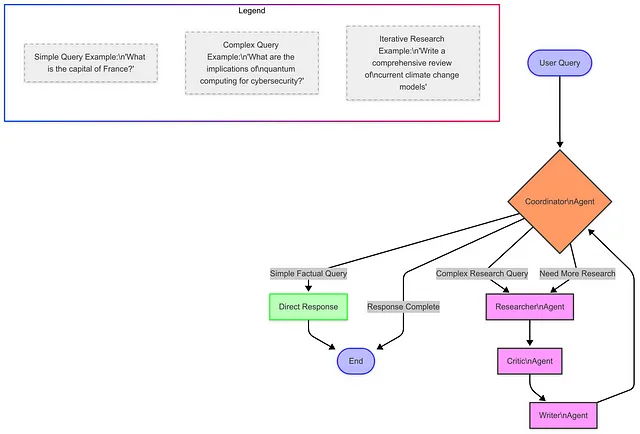
此图展示了查询可能采取的不同路径:
- 简单、事实性的问题会得到直接的回答
- 复杂的研究性问题则会通过我们的专业代理进行处理
- 一些查询可能需要多次研究迭代
亲眼目睹动态系统运行的过程
让我们看看我们的动态系统如何处理不同类型的查询:
查询 1 :“法国的首都是什么?”
Coordinator:
{
"reasoning": "This is a simple factual question asking for the capital of France. The answer is well-known and doesn't require in-depth research, critical analysis, or specialized writing.",
"next": "done"
}
系统响应 : “法国的首都是巴黎。”
查询 2 : “量子计算对网络安全有何影响?”
Coordinator:
{
"reasoning": "This query asks for complex information about quantum computing and its relationship to cybersecurity. It requires gathering detailed information, evaluating different perspectives, and synthesizing a comprehensive response.",
"next": "researcher"
}
系统随后将此查询依次传递给研究者、评论家和作家代理进行处理,再返回给协调者……
作者 : [撰写关于量子计算对加密、安全协议等方面影响的全面、结构严谨的内容]
协调员(在审阅作者输出后):
{
"reasoning": "The query has been thoroughly researched, critiqued, and synthesized into a comprehensive response that addresses the implications of quantum computing for cybersecurity from multiple angles.",
"next": "done"
}
系统响应: [作者的全面回复已发送给用户]
协调代理的价值
添加一个协调代理会以几种重要方式改变我们的系统:
- 效率 :简单查询可以跳过不必要的处理,提供更快的响应
- 适应性 :系统可以根据每个查询的性质采取不同的处理路径
- 迭代 :复杂查询可以经过多轮研究和优化
- 智能 :系统能够对如何处理信息做出高层次决策
- 可扩展性 :可以更轻松地向系统中添加新的专用代理
也许最重要的是,协调者使我们的系统感觉更像是与一个智能专家团队互动,而不是一个固定、机械的过程。
高级协调器实现
虽然我们的实现功能强大,但仍有多种方法可以使协调器更加复杂:
- 更多路由选项:允许协调者直接路由到任何代理,而不仅仅是研究者
- 反馈循环:使协调者能够识别差距并请求特定的额外研究
- 内存管理 :让协调者维护到目前为止所学到的内容的摘要
- 元学习 :允许协调者学习不同查询类型的最佳路径
- 多查询规划 :使协调者能够将复杂查询分解为子问题
协调者代理完善了我们的多代理研究助手,将其从一个顺序流程转变为一个动态、智能的系统。通过协调我们构建的专门化代理——研究者、批评者和撰写者——协调者创建了一个超越各部分总和的解决方案。
这种方法与高效的人类团队运作方式相似:专业专家在深思熟虑的协调下合作,以解决复杂问题。结果是一个能够快速提供简单答案、深入处理复杂问题,并根据每个独特情况调整自身方法的系统。
在你使用 LangGraph 构建自己的多智能体系统时,请记住,协调者是将一组智能体转化为真正智能、适应性强的系统的关键。
使用 LangGraph 的优势
使用 LangGraph 构建多代理系统具有以下优势:
- 结构化工作流:LangGraph 为定义代理如何交互提供了清晰的结构,使复杂系统更容易设计和维护。
- 状态管理 :该框架处理多个 LLM 调用中的状态管理,确保信息在代理之间正确流动。
- 条件路由:LangGraph 允许动态决策下一个应执行操作的代理,从而实现更加适应和响应的系统。
- 检查点 :内置的检查点功能使调试和恢复长时间运行的进程变得更加容易。
- 可扩展性 :基于图的方法使在系统演进过程中添加新代理或修改现有工作流变得更加容易。
来源:https://medium.com/cwan-engineering/building-multi-agent-systems-with-langgraph-04f90f312b8e


评论 (0)
还没有评论,来说两句吧!